


Introduction to Retrieval-Augmented Generation (RAG)
In the evolving landscape of AI and machine learning, Large Language Models (LLMs) have emerged as powerful tools capable of generating outputs across a wide range of tasks.
We use these powerful models daily for proofreading emails, code completion, and getting tasks done. Despite their exceptional capabilities, Large language models have some intrinsic limitations. They can provide misleading and sometimes hallucinated information since they have limited access to information. They often depend on potentially outdated information since their training data has a cutoff date. For example, If you ask an LLM "Who won the Euro 2024 finals?" it would not be able to provide a current or accurate answer if the event concluded after its last update, it might actually confuse this event to a previous event in the past and confidently provides a response - hence hallucination (when the response generated by AI contains misleading information presented as fact). This happens because the AI’s knowledge is static, limited to the information it was trained on up to its last update. Therefore, it can't provide real-time updates or outcomes of events occurring beyond that training cutoff, such as the results of Euros 2024 if it was trained before the event was decided.
This is where RAG comes in, it can significantly improve accuracy of these AI models by simply providing the access to relevant and up-to-date information. In this article, we will explore what RAG is and why it’s a key technology for leveraging LLMs for enterprise use cases.
Understanding RAG
RAG makes AI like Chat GPT smarter by allowing it to look up extra information in real-time, so you get more accurate answers without needing to retrain the entire model. Here’s a generic workflow:
- You ask the AI a question, like “What are the improvements in the latest product release?”
- The RAG system checks a special database designed for fast searching (called a vector database) to find related information.
- It combines your question with the retrieved information and sends it to the AI.
- The AI then generates a response based on both the question and the additional information.
This means that even if the AI wasn't initially trained on a specific data, like your internal product release documents, RAG allows it to access that data in real-time, giving you more relevant answers.
RAG offers several key benefits:
- Up-to-Date Information: LLMs become outdated quickly because they are only trained to a point in time. RAG enables access to live information at query time.
- Adaptability: RAG systems can be easily updated with new information without requiring retraining of the entire model, making them highly adaptable to changing circumstances. For example, imagine having to retrain your entire AI model every time there's a new product release—that would be costly and inefficient. The latest release notes can be quickly added and made available to the AI with RAG, so it can use the most up-to-date information without a complete retraining.
- Cost-Efficiency: Retraining large language models is both expensive and time-consuming. RAG offers a more cost-effective solution by allowing the core model to stay the same while only updating the external knowledge base.
- Developer Control: RAG provides developers with greater control over the information sources used by the AI. You can curate, filter, or prioritize specific sources to match the needs of your application. This level of control helps manage biases, ensures compliance with guidelines, and tailors responses to suit particular use cases or audiences.
- Accuracy: RAG improves the accuracy and reliability of AI responses by leveraging retrieved information from trusted sources which reduces the models chances of making mistakes. This is especially important in situations where being accurate is crucial, like in educational tools or customer support systems.
- Domain Specialization: RAG allows for easy specialization of general-purpose LLMs to specific domains. By providing domain-specific knowledge bases, a general LLM can become an expert in areas like law, medicine, or engineering without the need for extensive domain-specific training.
- Reduced Bias: By carefully curating the information sources used in RAG, it's possible to mitigate some of the biases that may be present in the LLM's training data. This can lead to more balanced and fair responses across a variety of topics.
How RAG Works
Think of RAG as a detective and the LLM as a storyteller. The detective (RAG) gathers clues, evidence, and historical records from various databases and knowledge sources. Once this information is compiled, the storyteller (LLM) crafts a coherent narrative, presenting a clear and engaging account.
Key Components of a RAG System:
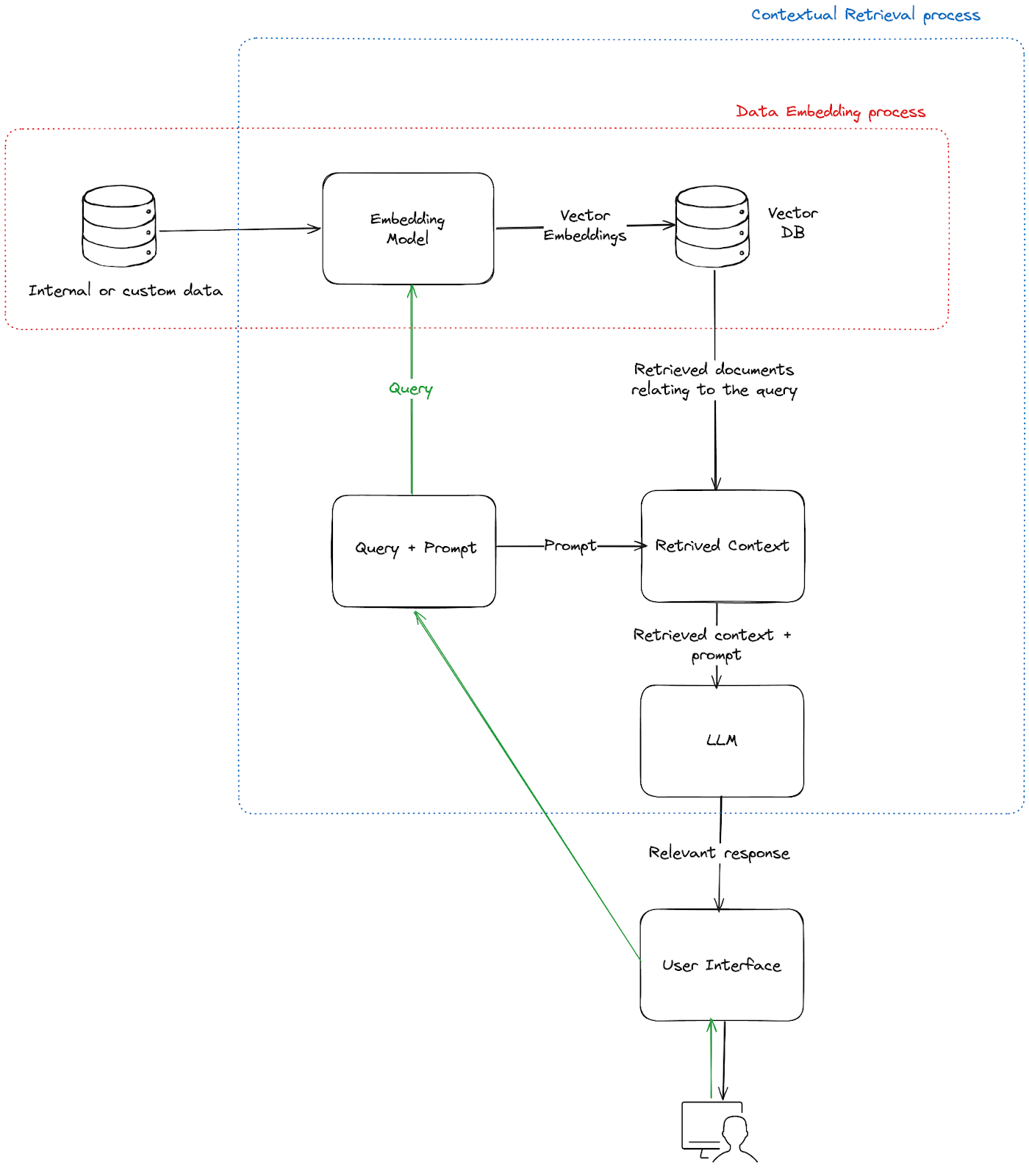
Data Collection: The first step is gathering all the necessary information for your specific application. For example, A company’s AI chatbot would need up-to-date information regarding all products, processes, FAQs to effectively provide relevant responses to users. It's important to ensure this data is complete, up-to-date, and properly formatted.
Data Chunking: Next, we break down the collected data into smaller, topic-focused pieces (data chunks), our system can quickly find what it needs without scanning the entire database for each query. This targeted approach speeds up processing and improves accuracy.
Document Embedding: For the system to understand and compare information (user query vs needed data chunks), we convert these data chunks into numerical formats (vectors). This conversion allows the system to grasp the similarity and relationships between different pieces of information, making retrieval more precise.
Indexing: To ensure quick access, we index these embedded documents in a vector database. This indexing process creates a searchable structure, allowing the system to retrieve relevant information faster based on similarity.
Retrieval: When a question is asked, the system compares it with the indexed chunks to find the most relevant information. This retrieval process ensures that the system pulls only what’s necessary to answer the question accurately.
Generation: Finally, a Large Language Model (LLM) generates an answer based on the retrieved context. The LLM uses the relevant chunks to craft a response that's specific to the question and based on the available information.
The above components of the RAG system illustrates a basic RAG system that focuses on indexing and retrieval. There are more complex Pre-retrieval techniques such as query routing, rewriting, expansion and Post-retrieval techniques that we will not explore in this article.
Example Architecture of a Basic RAG system
RAG vs. Prompt Engineering
While both techniques are valuable for adapting Large Language Models (LLMs) to specific tasks, they are best suited for different scenarios.
Prompt Engineering: This involves crafting clear and specific instructions for the LLM. It can be used independently or to enhance other techniques like fine-tuning and RAG. Well-designed prompts can significantly improve the quality and relevance of the LLM's output.
RAG (Retrieval-Augmented Generation): This technique involves supplementing the LLM with access to external knowledge or reference material in addition to the prompt. It is ideal for tasks where access to up-to-date or domain-specific information is crucial for generating relevant answers.
Practical use cases for organizations
Enhanced Customer Support: RAG systems can revolutionize customer service by providing intelligent, context-aware chatbots. These bots can access vast knowledge bases to answer complex queries, understand customer history, and provide personalized solutions 24/7. This should not only improve customer satisfaction but also reduce the workload on human support teams.
Smart Employee Assistants: Organizations can implement RAG-powered virtual assistants to help employees navigate internal policies, access relevant documents, and get quick answers to work-related questions. This can significantly boost productivity and reduce time spent searching for information.
Personalized Marketing: RAG systems can analyze customer data, purchase history, and browsing behavior to generate highly targeted marketing content. This includes tailored email campaigns, dynamic website content, and personalized product recommendations, which can lead to improved conversion rates and customer engagement.
Internal Data Conversational Agent: RAG systems can power conversational agents that allow employees to query internal databases and reports using natural language. This enables staff across departments to easily access and interpret complex data without needing specialized technical skills. For example, a manager could ask, "What were our sales figures for Q2 in the Southeast region?" and receive an accurate, contextualized response. This democratizes data access, speeds up decision-making, and reduces the burden on data analysis teams.
Conclusion
In conclusion, Retrieval-Augmented Generation (RAG) represents a significant advancement in the capabilities of Large Language Models (LLMs) by addressing some of their intrinsic limitations. By integrating a retrieval mechanism that allows access to up-to-date external knowledge, RAG enhances the accuracy, relevance, and reliability of LLM outputs. This approach not only mitigates the issue of outdated information and hallucinations but also offers cost-efficiency, adaptability, and improved developer control.
The benefits of RAG extend across various practical applications, from enhanced customer support and smart employee assistants to personalized marketing and internal data conversational agents. These applications demonstrate the transformative potential of RAG in improving efficiency, accuracy, and user satisfaction in enterprise settings.
We will touch on more advanced RAG concepts in future articles.

